
上位Kagglerに学ぶ〜画像コンペの戦い方〜|振り返り記事

博報堂テクノロジーズKaggle部は先日、Kaggleの画像コンペに特化したイベント「上位Kagglerに学ぶ〜画像コンペの戦い方〜」を開催しました。本記事では、その開催概要や当日の様子をレポートします!
第1部は上位KagglerによるLT(Lightning Talk)、第2部はパネルディスカッションという二部構成。オンライン・オフラインあわせて400名の応募があり、熱量の高いイベントとなりました。

イベント概要
本イベントは、単なる成功事例の紹介に留まらず、登壇者それぞれの着眼点や工夫、思考のプロセスに焦点を当てました。Kaggle経験者はもちろん、これから画像系コンペに挑戦する方にも実践的な学びを持ち帰っていただけるよう、検証設計、ハイパーパラメータチューニング、データ拡張などの要素について、上位入賞経験者の方々にお話しいただきました。
第1部:LTセッション
第1部では、福井 尚卿(tattaka)氏、和田 孝喜(ななち)氏、國府田 淳(JunKoda)氏の3名が、それぞれの視点から“画像コンペで勝つための土台と伸ばし方”を語りました。
福井尚卿 (tattaka)氏「画像コンペでのベースラインモデルの育て方」
tattaka氏は「画像コンペでのベースラインモデルの育て方」をテーマに、”良いベースライン”とは何か、実験回数を増やす方法、パラメータチューニング、精度を上げるためのテクニックなどについて発表しました。

和田 孝喜 (ななち)氏「敗北解法コレクション〜Expertだった頃に足りなかった知識と技術〜」
続いてななち氏は「敗北解法コレクション〜Expertだった頃に足りなかった知識と技術〜」と題して、金メダルを獲得する前の自身の経験を振り返り、当時不足していた技術や知識について発表されました。

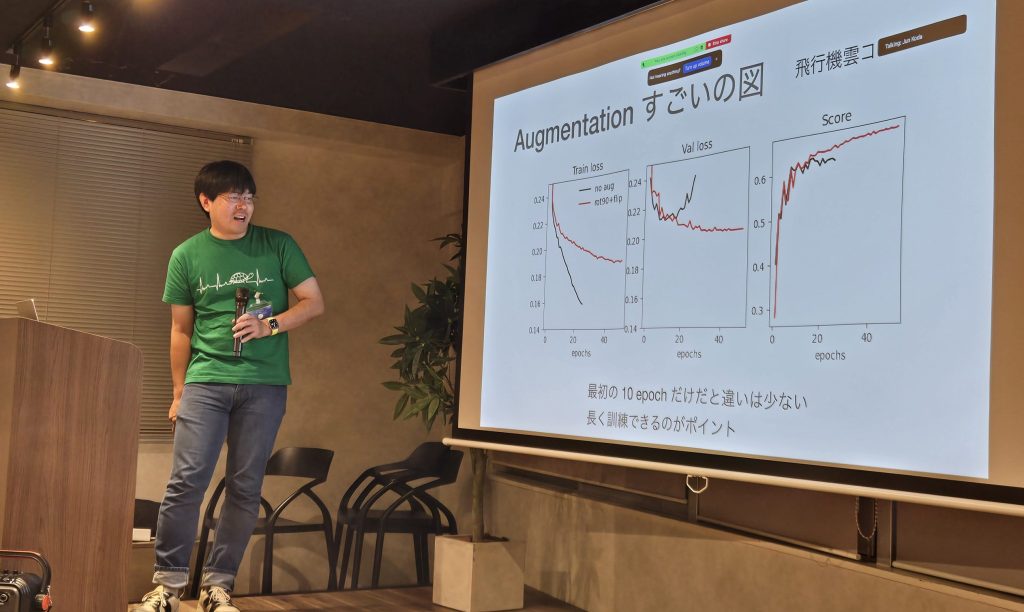
國府田淳 (JunKoda)氏「画像ディープラーニングコンペの基本」
最後にJunKoda氏は「画像ディープラーニングコンペの基本」というテーマで、過去の自身の経験を元に、主にaugmentationが役に立つ場面や逆にやってはいけないことなどを深堀りした発表を行いました。
第2部:パネルディスカッション
第2部では、弊社社員坂本がモデレーターとなり、登壇者3名とパネルディスカッションを行いました。画像コンペの楽しみ方から重要なテクニックまでざっくばらんに語り合いました。

画像コンペの楽しさ
画像タスクの多様性(分類、セグメンテーション、検出、3Dなど)が思考の幅を広げ、毎回「どう解くか」を設計する過程そのものが面白さにつながる、という点で意見が一致しました。とりわけ3D領域は定石が少なく、思い通りにいかない難しさが学習動機を生みます。また、モデルの出来栄えがスコアとしてはっきり返ってくる“手応えの明確さ”も、継続の原動力として挙げられました。
EDAでは何を行うか
まず「見る」ことが出発点です。大量のサンプルを確認し、画像・ラベル・マスクを並べて整合性を確認します。医療系のように画素値レンジが特殊な場合は、単純な可視化に加えてヒストグラムなどで分布を把握します。外れ値の特定や、局所情報と大局情報のどちらが本質的かの見極めを通じて、必要な解像度と特徴量のスコープを定めます。加えて、ラベル分布の不均衡や枚数の偏りを早期に把握し、改善に反映することが重視されました。
ベースラインの作り方とかける時間
ベースラインの作り方は大きく二通りに整理されました。勝ち筋が見えれば最小構成で素早く組み、検証を回しながら差し替えポイントを育てる方式。もう一つは、公開Notebookを参考にしつつ、自分のテンプレート(例:PyTorch Lightning)に落とし込み、ゼロから再現して理解を深める方式です。 所要時間はコンペ依存で、数日で固まるケースもあれば、2〜3ステージ構成や複雑な課題では1か月規模になることも珍しくありません。
モデルアーキテクチャの選択
CNN、とくにConvNeXt系を初手にためす意見が多く、アンサンブル時に別系統(例:EfficientNet)を混ぜる発想が語られました。 2.5Dと3Dの選択は、スライス数や“注目すべき断面を特定できるか”という前提次第で使い分けることが多いようです。サンプル数が不足するなら、2Dの特徴を時系列モデル(LSTM/RNNなど)で集約する段階的構成も有効とされました。全体として、ImageNetなどの事前学習を活用したスタートが堅いという議論もありました。
公開情報(Public Notebook/Discussion)の扱い
最初から手法を丸ごと模倣するのではなく、まず自前のベースラインを構築し、行き詰まりや検証の違和感が出た段階で公開情報を参照する姿勢が多かったです。特に「データ不具合に関するスレッド」は早期にチェックすべき必読情報です。 Notebookはモデルよりも前処理の知見(とりわけ医療系のドメイン知識)を得る目的で活用し、手元のパイプラインに適切に移植して検証する、という使い分けが共有されました。公開手法と似た実装でも差が出る場合は学習率など基本設定を疑うといった“検証の当たり前”も再確認されました。
参加状況と所感
オンライン・オフライン合計で400名の応募が集まりました。初学者は“まず押さえるべき基礎”を、経験者は“勝ち筋の再現性を高める運用”を、それぞれ持ち帰っていただけたと感じています。小さく速く回す実験設計と、堅実な検証という二つの柱が、画像コンペで上位に迫る王道であることを、登壇と議論を通じて改めて確認できました。
最後に
最後に、本イベントにご登壇いただいたtattaka様、ななち様、JunKoda様に心より感謝申し上げます。皆様の貴重な知見の共有に厚く御礼申し上げます。

登壇者(敬称略)
福井 尚卿(tattaka)
「画像コンペでのベースラインモデルの育て方」
https://speakerdeck.com/tattaka/hua-xiang-konhetenohesurainmoterunoyu-tefang
和田 孝喜(ななち)
「敗北解法コレクション〜Expertだった頃に足りなかった知識と技術〜」
國府田 淳(JunKoda)
「画像ディープラーニングコンペの基本」
https://speakerdeck.com/junkoda/hua-xiang-deipuraningukonpenoji-ben
今回の運営について(博報堂テクノロジーズKaggle部)
博報堂テクノロジーズでは、2024年10月に「Kaggle部」を設立いたしました。設立の背景には、同年9月に社内で部活動制度が開始されたことがあります。当時、社内には技術的な横のつながりを持つ活動がまだ少なく、また他社においてKaggle部が盛り上がりを見せている状況を踏まえ、当社においても有志が集まり創設に至りました。
Kaggle部は、部員それぞれのレベルに応じたメダルの獲得を目標として活動しています。メダルを獲得することで技術力を高め、その知見を各部署に持ち帰ることで、博報堂テクノロジーズのソリューションへ還元することを目指しています。
今後も、勉強会の開催やチームでのコンペティション参加を通じて、部員が目標とするメダルや称号を獲得できるよう活動を継続してまいります。さらに、Kaggleで得られた知見や経験を通じて、個人の成長にとどまらず、当社の技術力の向上と社外への発信にもつなげていきたいと考えています。
著:Kaggle部部長 坂本 龍士郎

Share:










